Publications
Rethinking Page Table Structure for Fast Address Translation in GPUs: A Fixed-Size Hashed Page Table
2024 International Conference on Parallel Architectures and Compilation Techniques (PACT 2024)
Sungbin Jang
Junhyeok Park
Osang Kwon
Yongho Lee
Seokin Hong
Rethinking Page Table Structure for Fast Address Translation in GPUs: A Fixed-Size Hashed Page Table
Modern GPUs rely on multi-level Radix Page Tables (RPTs) to translate virtual addresses, but irregular applications incur frequent TLB misses and sequential pointer-chasing walks that severely degrade performance. Emerging workloads—such as graph analytics and deep learning—exacerbate this bottleneck by generating thousands of concurrent page table walk requests, leading to long queueing delays and underutilized GPU compute resources
The Problem: Inefficiency of Radix Page Tables in GPUs
In GPUs, applications have large memory footprint and irregular memory access pattern, shows high last-level TLB miss rate due to massive parallelism of GPUs. These TLB misses require page table walk to get virtual-to-physical address mappings. Generally, conventional GPUs adopt multi-level Radix Page Tables (RPTs) to store these mappings. Each RPT lookup may incur up to four memory accesses before the actual data fetch, and with five-level page tables in modern systems, this overhead grows further. Page Walk Caches mitigate some pressure but still suffer high miss rates (average 33.8% on irregular workloads), limiting their effectiveness
The Proposed Solution: FS-HPT, a Fixed-Size Hashed Page Table
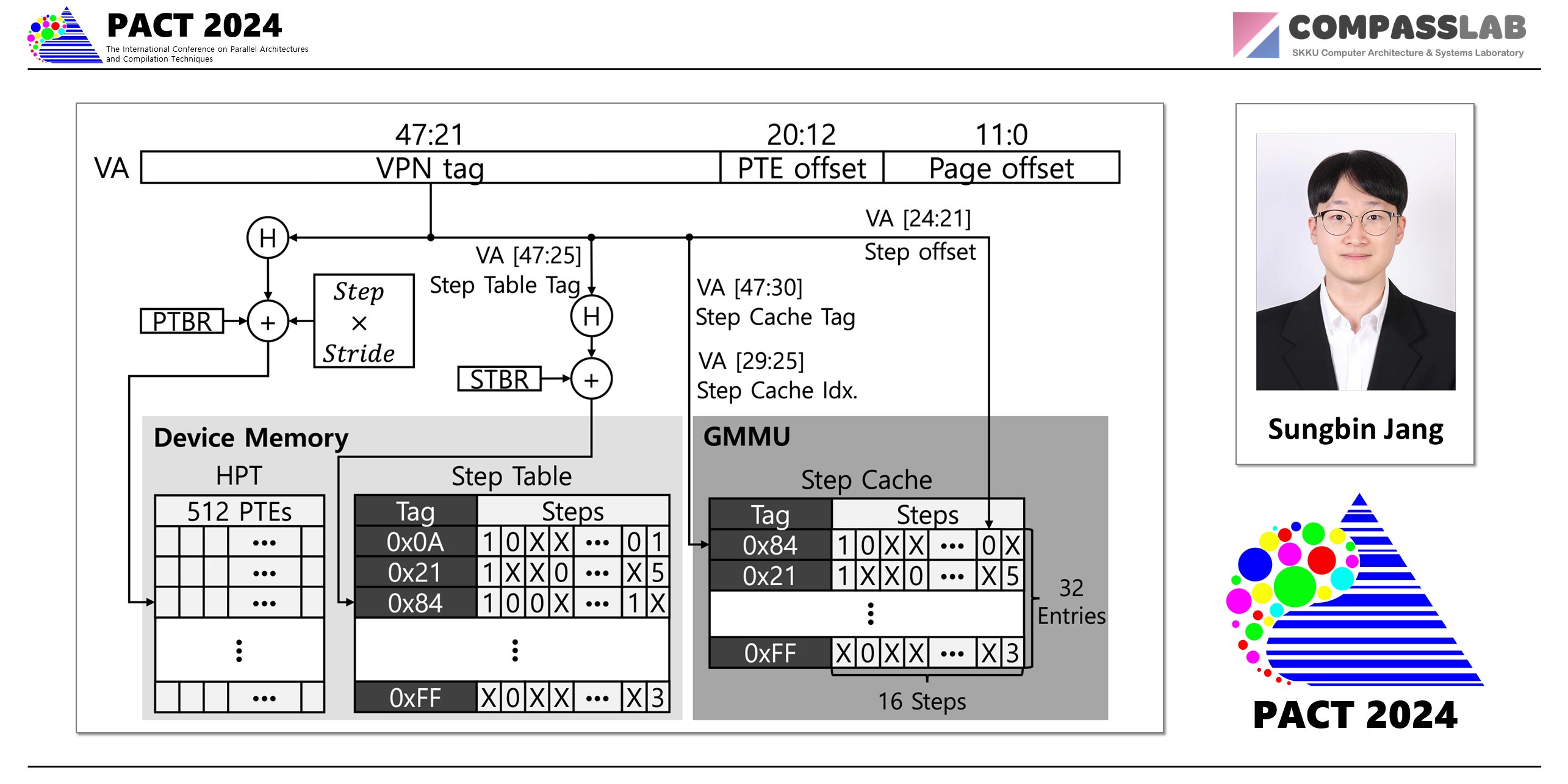
In CPU domain, Hashed Page Tables (HPTs) rise a effective and practical solution due to their ability to access page table only a single memory access. However, adpoting HPTs introduces a key challenge: hash collisions. FS-HPT resolves the hash collision challengs by leveraging the key insight: The GPU only needs to store PTEs for pages resident in VRAM therefore the hash table never needs complicated techniques for resolving hash collisions.
The key idea is simple yet powerful:
Fixed-Size Hashed Page Table (FS-HPT): Replaces RPTs with a large, fixed-size hash table in device memory. Because the GPU only needs to store PTEs for pages resident in VRAM—and hot remote mappings saturate quickly—the hash table never needs dynamic resizing.
pen Addressing with Step Table & Step Cache: Collisions are resolved via open addressing; a compact step table records probe offsets, and a 32-entry step cache (repurposed from the MMU cache) ensures over 99% hit rates on recent entries, reducing most lookups to a single memory access.
emote PTE Eviction & Victim Buffer: To bound the load factor, cold remote mappings are evicted based on an LRU policy and held in a scalable radix-tree victim buffer, avoiding costly page faults on reaccesses.
The Impact: Massive Performance Gains
Evaluation on diverse graph and scientific benchmarks shows that FS-HPT:
- Reduces average page walk latency by 22.2%,
- Lowers memory references per walk from 1.35 to 1.01, and
- Achieves an average application speedup of 27.8% over four-level RPTs—nearly matching an ideal Page Walk Caches.
FS-HPT demonstrates that HPTs can effectively eliminate the pointer-chasing bottleneck in GPU virtual memory, offering a scalable path for future high-throughput accelerators.
Keywords