Publications
A Case for Speculative Address Translation with Rapid Validation for GPUs
57th IEEE/ACM International Symposium on Microarchitecture (MICRO 2024)
Junhyeok Park
Osang Kwon
Yongho Lee
Seongwook Kim
Gwangeun Byeon
Jihun Yoon
Prashant J. Nair
Seokin Hong
A Case for Speculative Address Translation with Rapid Validation for GPUs
Modern GPUs rely on a unified address space to efficiently share data with CPUs, but this comes at a cost. The process of translating virtual memory addresses to physical ones creates a significant performance bottleneck, especially for complex applications. This address translation overhead can slow down GPUs by up to 34.5%, causing their powerful cores to stall while waiting for data.
The Problem: The Address Translation Waiting Game
When a GPU thread needs data from memory, it must first get the correct physical address. A miss in the TLB cache triggers a slow, multi-step “page table walk”. This process is so slow that it can nearly double the memory access latency (an increase of up to 1.96x). Because thousands of threads can request translations at once, the GPU’s ability to hide latency with parallelism is overwhelmed, leaving its cores idle and waiting.
The Proposed Solution: Avatar, Speculation with Rapid Validation
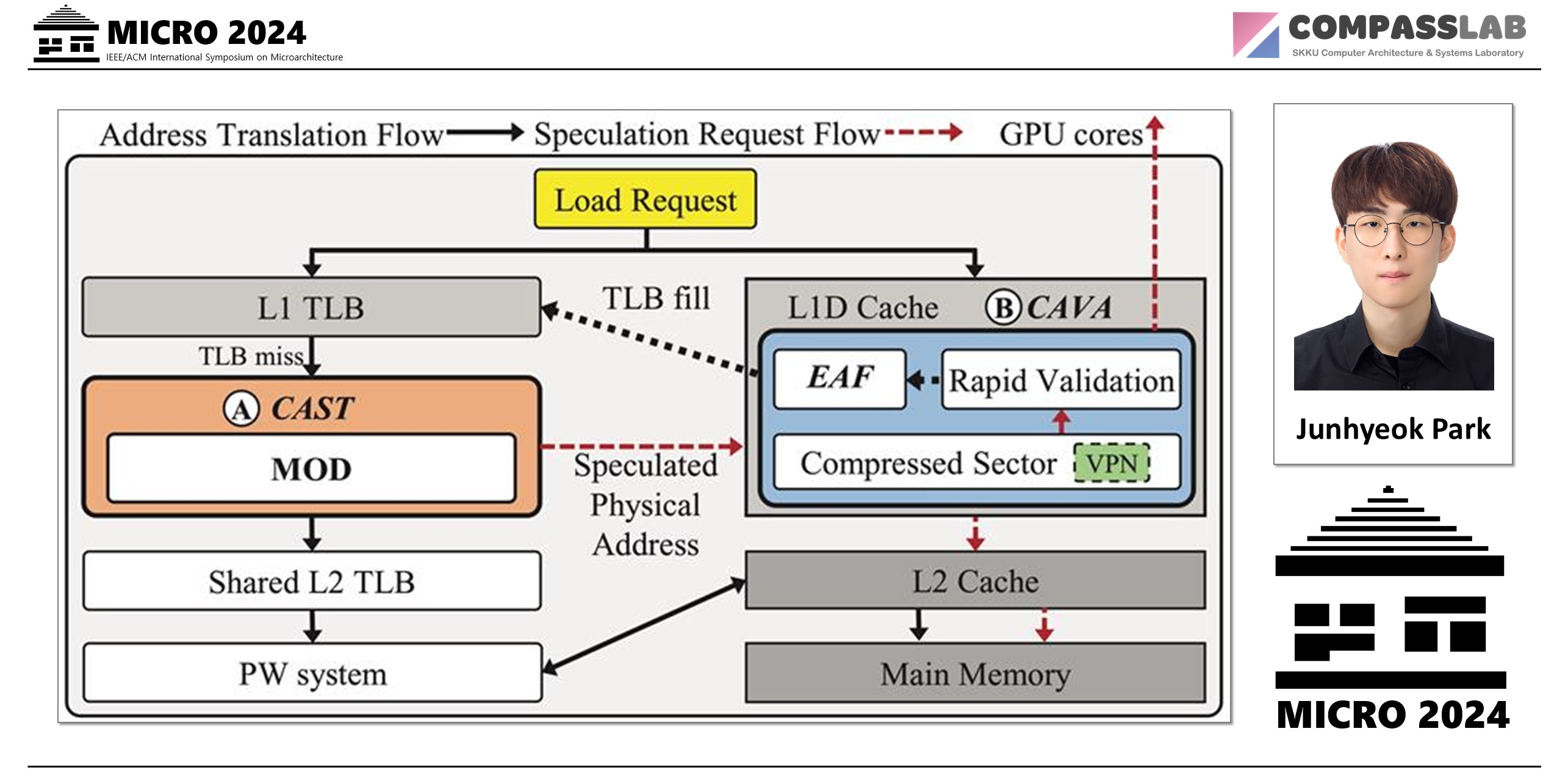
To solve this fundamental bottleneck, this paper introduces Avatar, a novel framework that hides the address translation delay using speculation and rapid validation. Instead of waiting for the slow page walk to finish, Avatar makes an “educated guess” to start fetching data immediately.
The key idea is simple yet powerful:
Contiguity-Aware Speculative Translation (CAST): This mechanism leverages the fact that memory is often allocated in contiguous blocks. Based on this, CAST speculatively translates a virtual address into a physical one, allowing the data fetch from memory to begin right away while the official translation happens in the background.
In-Cache Validation (CAVA): The challenge is that GPUs cannot use this speculatively fetched data until it is confirmed to be correct. CAVA provides a rapid validation solution by cleverly embedding page mapping information into data cache lines using compression. When the data arrives, CAVA instantly checks this embedded “smart tag” to validate the speculation, allowing the GPU to use the data almost immediately.
The Impact: Massive Performance Gains
By effectively eliminating the time spent waiting for address translation, Avatar unlocks significant performance. The evaluation demonstrates that Avatar:
- Achieves a high speculation accuracy of 90.3%.
- Improves overall GPU performance by 37.2% on average.
Avatar demonstrates that a speculative approach with rapid validation is a powerful and effective method to overcome one of the key performance hurdles in modern GPU systems.
Keywords