Publications
Zebra: Leveraging Diagonal Attention Pattern for Vision Transformer Accelerator
2025 Design, Automation & Test in Europe Conference & Exhibition (DATE 2025)
Sukhyun Han
Seongwook Kim
Gwangeun Byeon
Jihun Yoon
Seokin Hong
Abstract
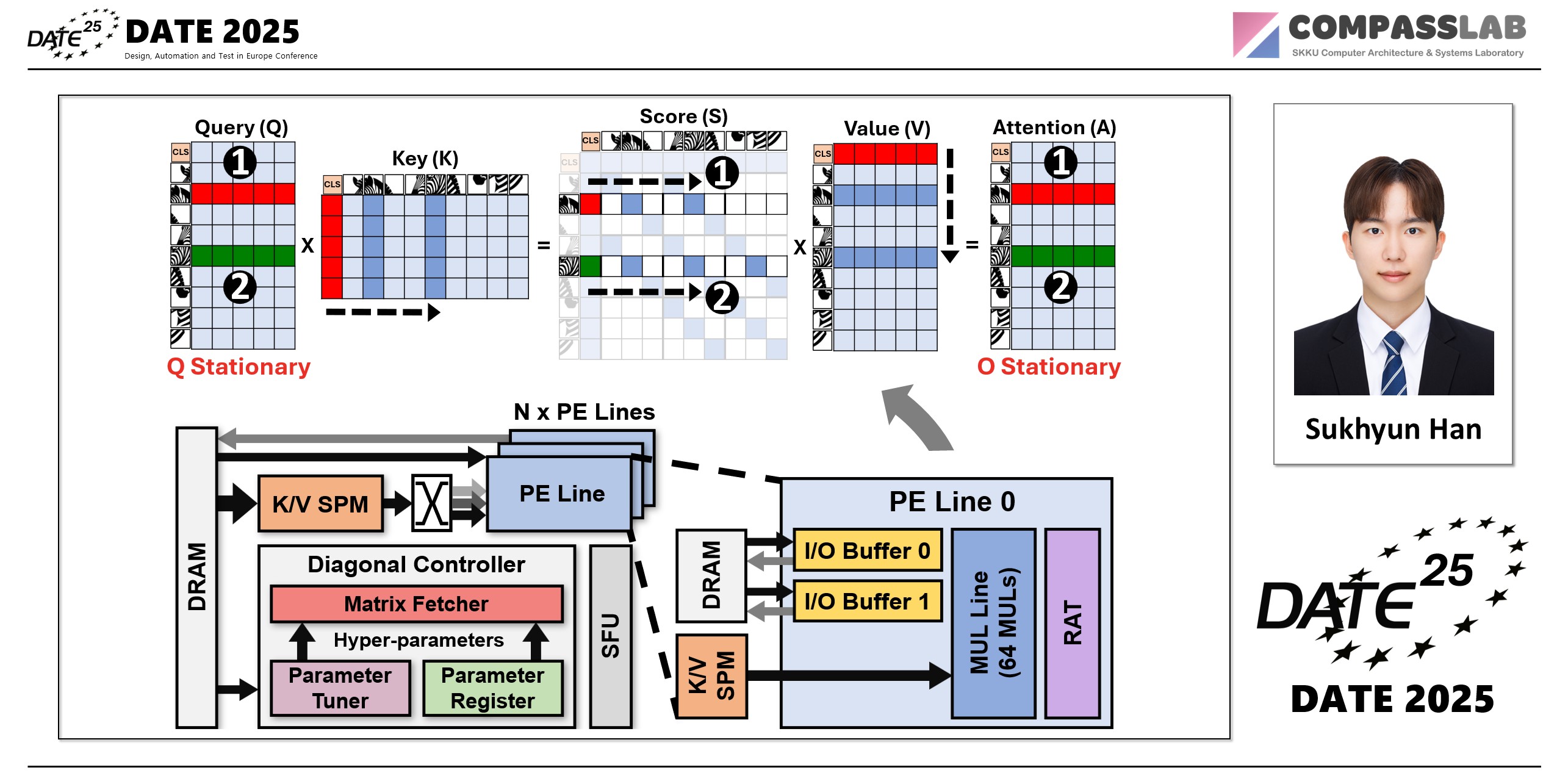
Vision Transformers (ViTs) have achieved remarkable performance in computer vision, but their computational complexity and challenges in optimizing memory bandwidth limit hardware acceleration. A major bottleneck lies in the self-attention mechanism, which leads to excessive data movement and unnecessary computations despite high input sparsity and low computational demands. To address this challenge, existing transformer accelerators have leveraged sparsity in attention maps. However, their performance gains are limited due to low hardware utilization caused by the irregular distribution of non-zero values in the sparse attention maps. Self-attention often exhibits strong diagonal patterns in the attention map, as the diagonal elements tend to have higher values than others. To exploit this, we introduce Zebra, a hardware accelerator framework optimized for diagonal attention patterns. A core component of Zebra is the Striped Diagonal (SD) pruning technique, which prunes the attention map by preserving only the diagonal elements at runtime. This reduces computational load without requiring offline pre-computation or causing significant accuracy loss. Zebra features a reconfigurable accelerator architecture that supports optimized matrix multiplication method, called Striped Diagonal Matrix Multiplication (SDMM), which computes only the diagonal elements of matrices. With this novel method, Zebra addresses low hardware utilization, a key barrier to leveraging the diagonal patterns. Experimental results demonstrate that Zebra achieves a 57x speedup over a CPU and 1.7x over the state-of-the-art ViT accelerator, with similar inference accuracy.
Keywords