Publications
PIMPAL: Accelerating LLM Inference on Edge Devices via In-DRAM Arithmetic Lookup
2025 Design Automation Conference (DAC 2025)
Yoonho Jang
Hyeongjun Cho
Yesin Ryu
Jungrae Kim
Seokin Hong
PIMPAL: Accelerating LLM Inference on Edge Devices via In-DRAM Arithmetic Lookup
Following the development of technology, the computing devices becomes much faster while the memory have larger capacity. This fact leaves the computing devices in idle time by waiting data from the memory, since the data transfer speed cannot follow computing speed, called “memory wall”. Processing-In-Memory (PIM) techniques are in the spotlight for solving memory wall challenge in modern computing systems, especially in LLM inference.
The Problem: Inefficiency in previous PIM devices
To enable PIM in memory device, the representative memory manufacturing companies developed their own PIM devices by integrating processing units within memory. Unfortunately, this approach suffers from significant area overhead of processing units, almost 50% permanent capacity loss in devices. The main reasons is the feature of memory fabrication technology, which is not affordable to make processing logic.
Another PIM research have focused on Lookup Table (LUT) method, which stores pre-computed data and fetching the needed elements by operands. This approach in PIM utilizes memory cell as Lookup Table, implemented with simple decoding logic. However, prior LUT-based research is not practical in real system due to low speed and low bit-precision. Since they do not consider row activation overhead, frequent LUT row activation degrades performance. Also, as the entry of LUT effects on LUT size, it is hard to support LUT about 16-bit data format, requiring 8GB LUT.
The Proposed Solution: PIMPAL, A Parallel Arithmetic Lookup
To address these issues in LUT-based PIM, this paper introduces PIMPAL, a novel LUT-based PIM architecture for supporting high speed like processing unit and high bit-precision. PIMPAL achieves these goals based on two mechanisms: LCM and LAG.
The key idea is simple yet powerful:
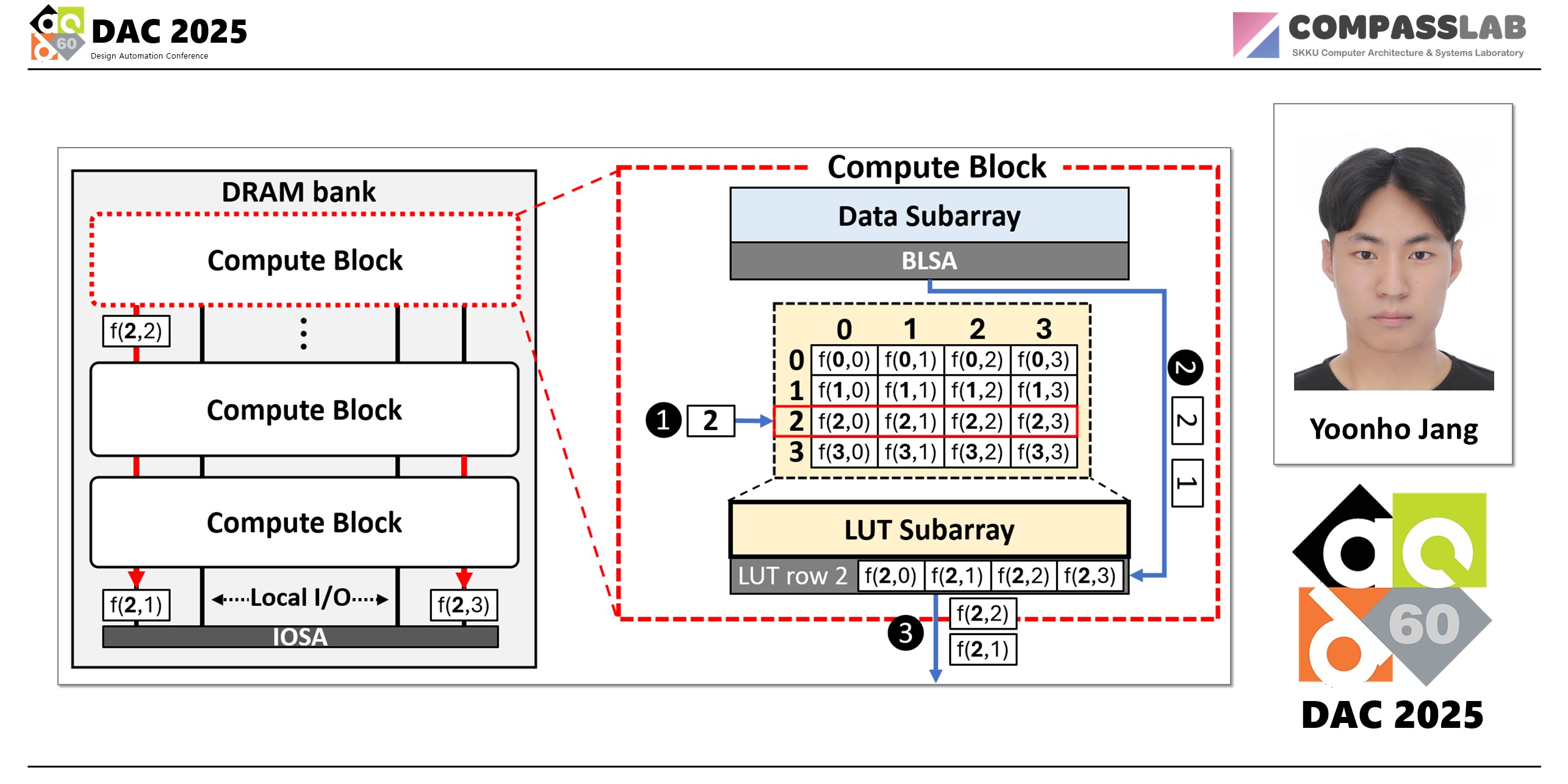
Locality-aware Compute Mapping (LCM): This mechanism focuses on reducing frequent LUT row activation. LCM is based on column-major processing method in matrix-vector multiplication. As this method reuses a vector element with data in the same column of matrix, PIMPAL activates LUT row with the vector element and decodes LUT elements by matrix data in corresponding column. LCM can reduce the total number of LUT row activation from # of matrix data to # of vector elements.
LUT Aggregation (LAG): LAG mechanism targets for supporting high bit-precision LUT operation such as BF16. LAG reduces LUT size about this format by decomposing the data based on specification of floating point. In floating point arithmetic operation, the data divides into three different parts (sign, exponent and mantissa) and the results can be earned by combining their independent operation results. Therefore, LAG generates multiple LUT about decomposed data and generates results by aligning LUT elements decoded from different LUT.
The Impact: Massive Performance Gains
By reducing the number of LUT row activation, PIMPAL achieves significant performance improvement. The evaluation demonstrates that PIMPAL:
- Shows 17.5x speedup than prior LUT PIM.
- Achieves similar performance and energy efficiency with unit-based PIM.
- Reduces area overhead by 40% than unit-based PIM.
PIMPAL demonstrates that LUT-based method can show high performance as fast as unit-based approach and be practical in real computing system due to little area overhead.
Keywords