Publications
SoftWalker: Supporting Software Page Table Walk for Irregular GPU Applications
58th IEEE/ACM International Symposium on Microarchitecture (MICRO 2025)
Sungbin Jang
Junhyeok Park
Yongho Lee
Osang Kwon
Donghyun Kim
Juyoung Seok
Seokin Hong
SoftWalker: Supporting Software Page Table Walk for Irregular GPU Applications
Modern GPUs are the powerful engines behind today’s most demanding applications, from AI and scientific computing to stunning graphics. But as these applications become more complex, with irregular data access patterns, GPUs are hitting a critical traffic jam in their memory systems. This bottleneck, known as address translation, can cause the entire GPU to stall.
The Problem: A Traffic Jam Inside the GPU
Every time a GPU needs data from memory, it has to translate a virtual memory address to a physical one. This process is usually fast, thanks to a cache called the Translation Lookaside Buffer (TLB). However, irregular applications, such as graph analytics or sparse matrix computations, cause a massive number of TLB misses. When a TLB miss occurs, a specialized hardware unit called a Page Table Walker (PTW) must step in to find the correct address in main memory. The problem is that a GPU has only a small, fixed number of these hardware PTWs. When thousands of threads miss in the TLB simultaneously, they all have to line up and wait for one of the few PTWs to become available. This creates an enormous “queueing delay”. The paper’s analysis reveals that for irregular workloads, this waiting time accounts for a staggering 95% of the total address translation latency. The GPU’s powerful processing cores are left idle, simply waiting in line.
The Proposed Solution: SoftWalker, A Software-Defined GPS for Data
To solve this fundamental bottleneck, this paper introduce SoftWalker, a novel framework that shifts page table walking from rigid, fixed-function hardware to flexible, scalable software. Instead of waiting for a hardware PTW, SoftWalker repurposes the GPU’s own massive thread-level parallelism to do the job.
The key idea is simple yet powerful:
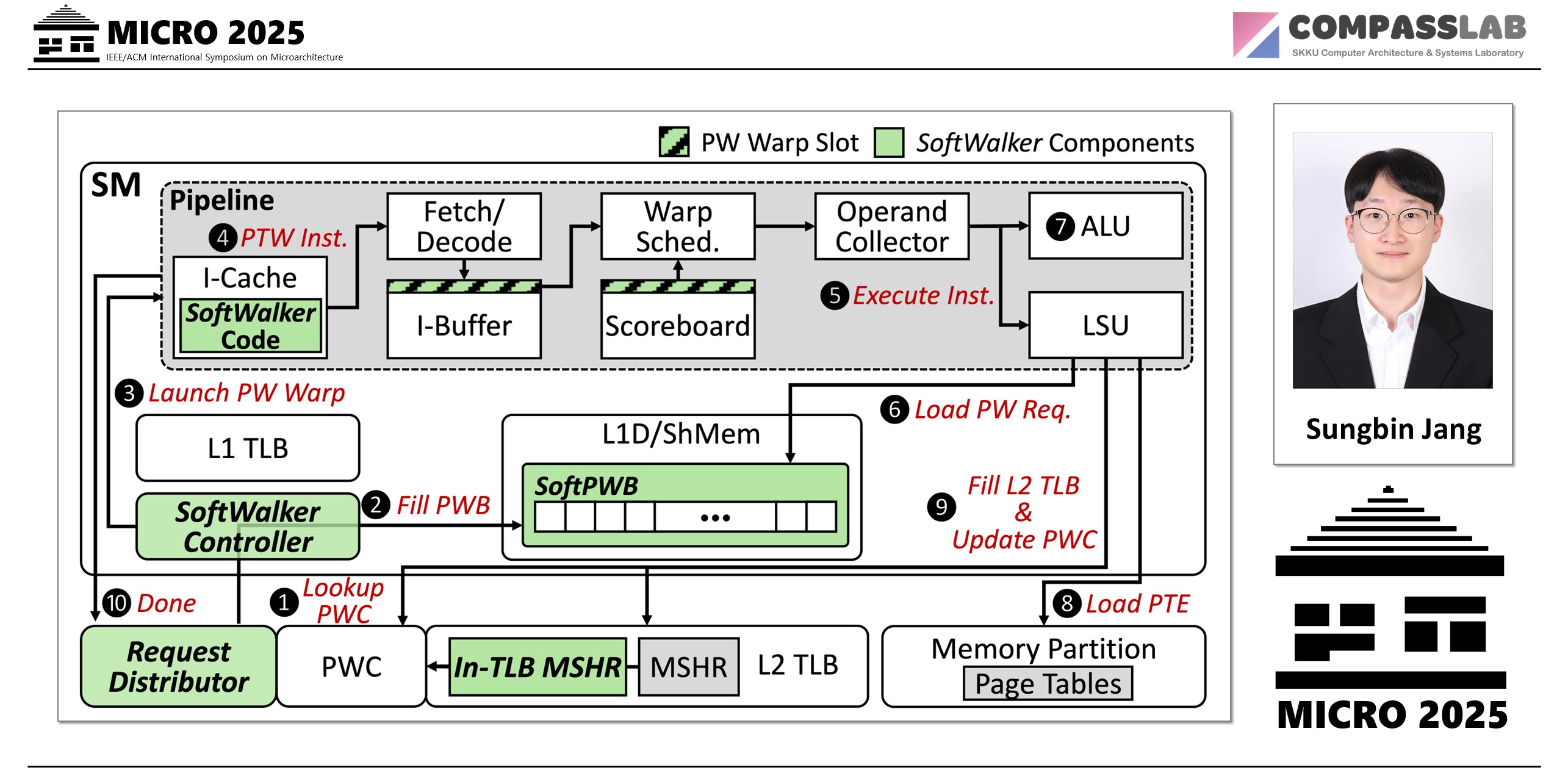
On-Demand Software Walkers: When a TLB miss occurs, SoftWalker dynamically launches specialized, lightweight software threads called “Page Walk Warps” (PW Warps). These warps run on the GPU’s cores during idle cycles that would have otherwise been wasted waiting. It’s like having thousands of on-demand delivery drones to fetch addresses instead of waiting for a few overworked trucks.
In-TLB MSHRs: This massively parallel approach creates a new challenge: the hardware buffers that track pending misses (MSHRs) quickly fill up. SoftWalker introduces a key innovation called In-TLB MSHRs, which cleverly repurposes underutilized L2 TLB entries to act as temporary MSHR slots. This expands the capacity to handle thousands of concurrent misses without expensive hardware changes.
The Impact: Massive Performance Gains
By eliminating the queueing bottleneck, SoftWalker unlocks significant performance. The evaluation demonstrates that SoftWalker:
- Reduces the average page walk latency by 72.8%.
- Achieves an average application speedup of 2.24x across a diverse set of workloads.
- Delivers an incredible 3.94x average speedup for the most challenging irregular applications.
SoftWalker demonstrates that a software-defined approach is a scalable and highly effective solution to one of the most significant challenges in future GPU memory systems.
Keywords