Publications
Boosting LLC Bandwidth Utilization in GPUs through Adaptive Fine-Grained Data Migration
2026 Design, Automation and Test in Europe Conference (DATE 2026)
Jihun Yoon
Sungbin Jang
Seokin Hong
Abstract
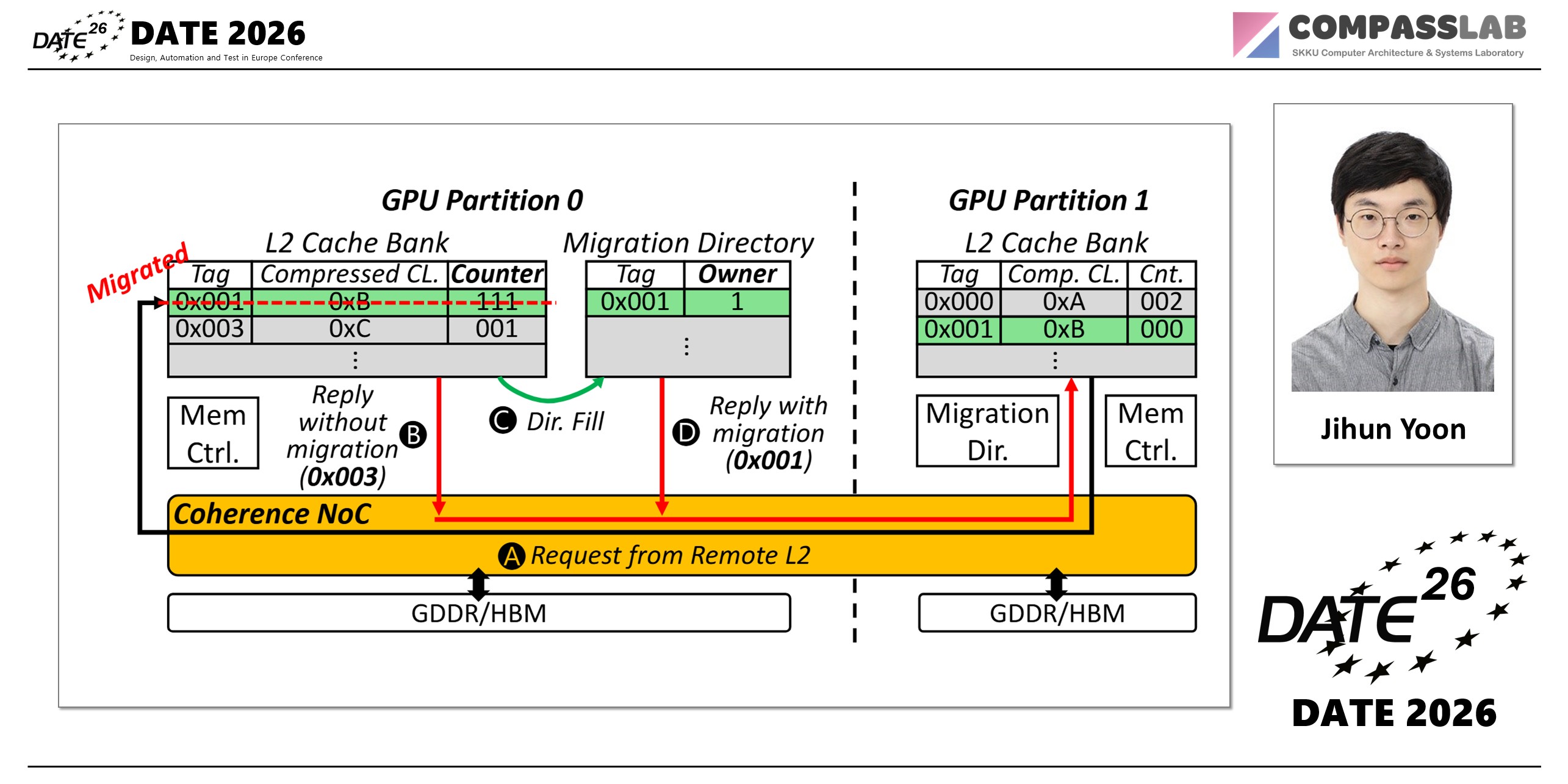
Modern server-grade GPUs (e.g., NVIDIA A100) integrate hundreds of cores and tens of memory partitions, providing massive compute capability and memory bandwidth. However, the increased scale amplifies interconnect overhead between cores and memory partitions. To mitigate this, NVIDIA A100 clusters multiple cores and memory partitions into two large groups, thereby simplifying interconnect complexity. Unfortunately, this partitioning introduces a new limitation: remote partition accesses. A core accessing a remote memory partition incurs higher latency and lower bandwidth compared to local accesses. In this paper, we propose a cacheline migration mechanism across partitions to alleviate remote memory access overhead. Our design is motivated by two key observations: (1) conventional GPUs employ limited and often ineffective optimizations for remote access handling, and (2) GPU applications typically exhibit high temporal locality, where a specific partition of cores makes frequent memory accesses for the same data within short time intervals. Leveraging these insights, we dynamically migrate cachelines to the local partition where the requesting core resides. Experimental results demonstrate that our approach achieves up to 1.24× speedup over the baseline with NVIDIA A100-like replication, highlighting its effectiveness in reducing remote access penalties.
Keywords