Research
Computer Architecture
Computer Architecture is a core research area that focuses on the design and optimization of computing systems, including processors, memory hierarchies, input/output devices, and their interconnections. It aims to enhance performance, power efficiency, and scalability to meet the demands of modern applications such as AI, big data, and cloud computing.
Key topics include instruction set architecture, microarchitecture, pipelining, multi-core processors, and parallel processing.
Researchers also explore innovations like heterogeneous computing, virtual memory system and cache management to optimize data flow and processing efficiency, shaping the future of high-performance computing systems.
Memory System
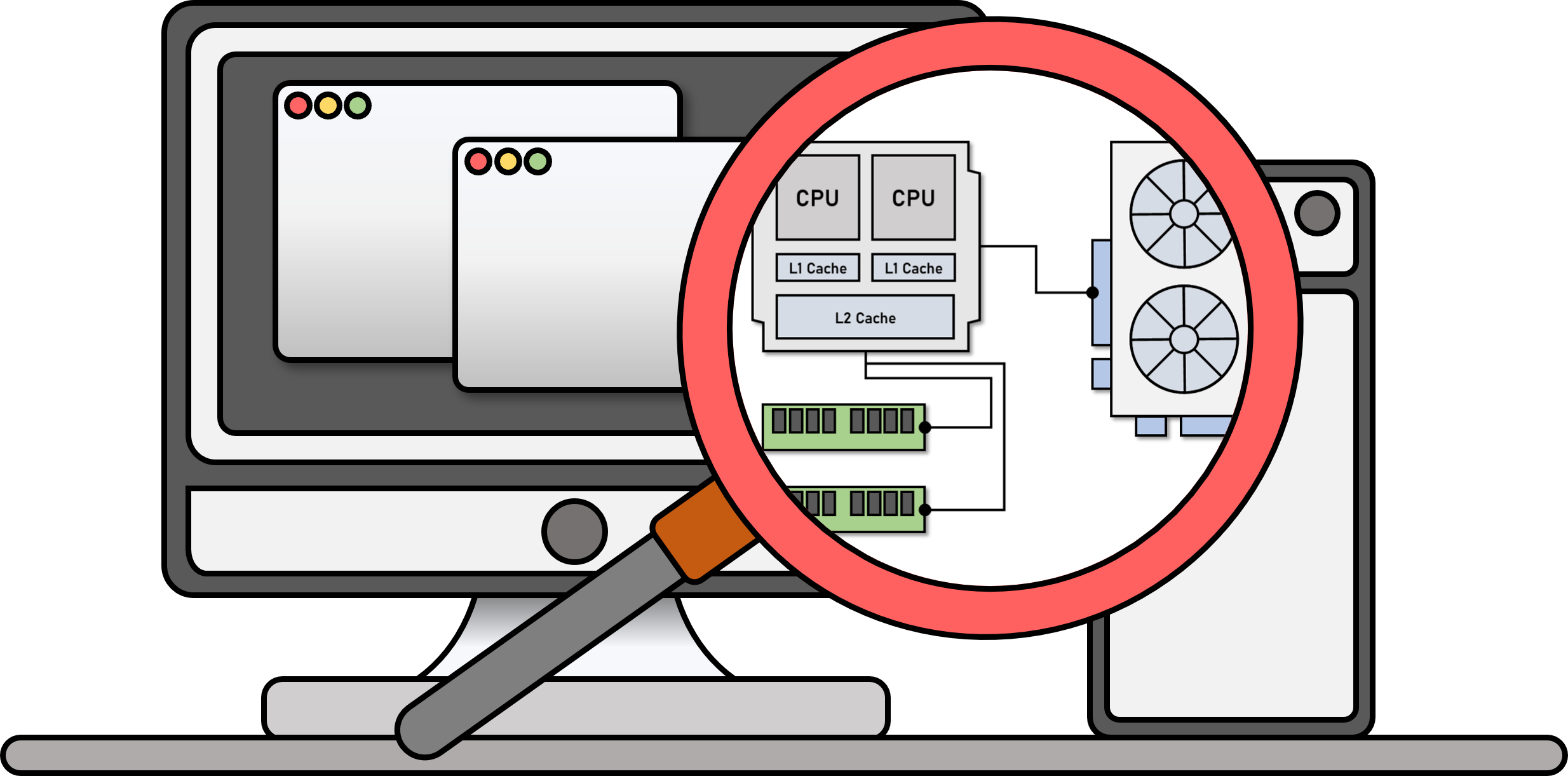
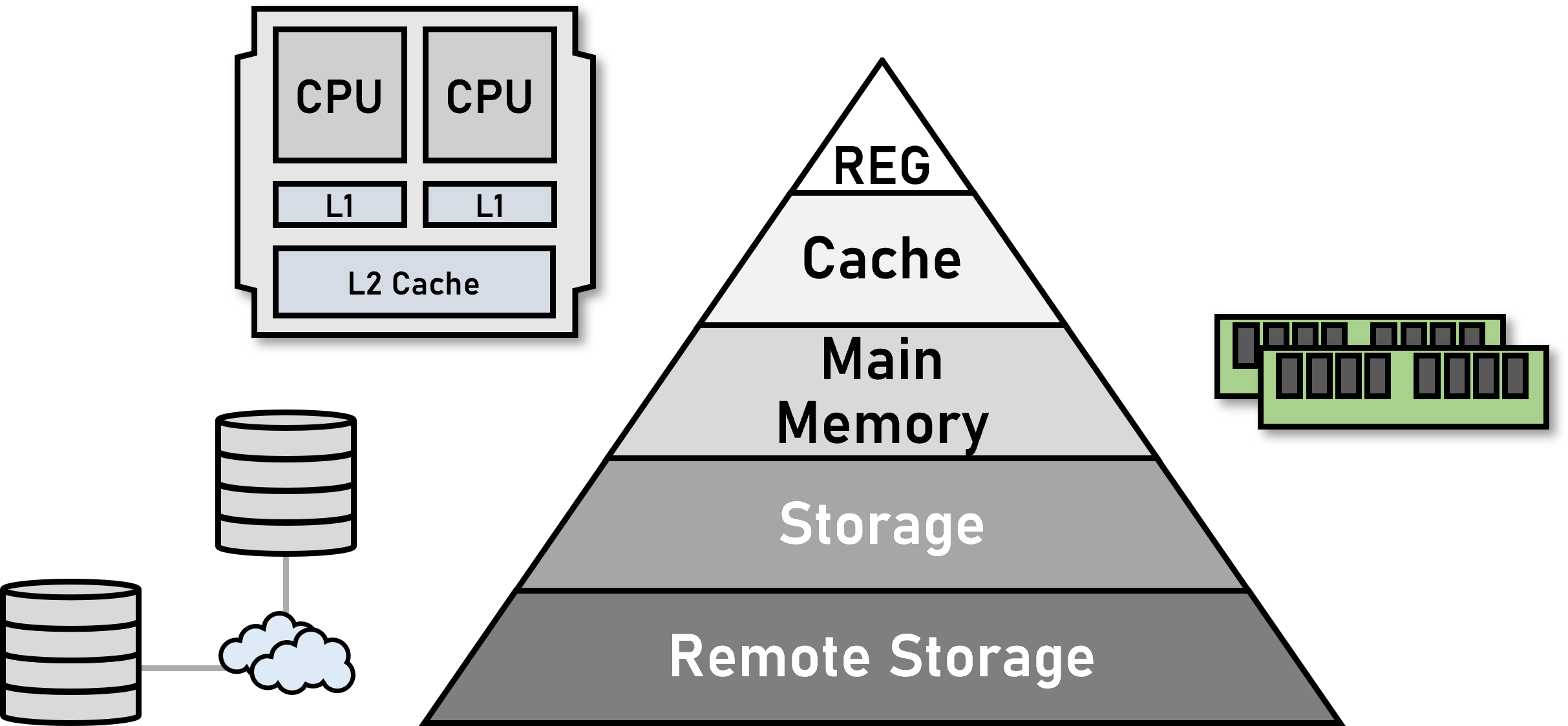
Memory Systems research focuses on the design and optimization of memory hierarchies to balance speed, capacity, and energy efficiency in computing systems. It covers components like caches, main memory (DRAM), and secondary storage (SSDs), aiming to reduce latency and increase bandwidth for data-intensive applications.
Key research areas include techniques such as memory prefetching, dynamic allocation, and new non-volatile memory technologies like phase-change memory (PCM).
Memory systems also address challenges in maintaining consistency and coherence across multi-core processors. This research is crucial in managing large-scale data workloads in modern applications like AI, big data, and cloud computing.
Operating Systems
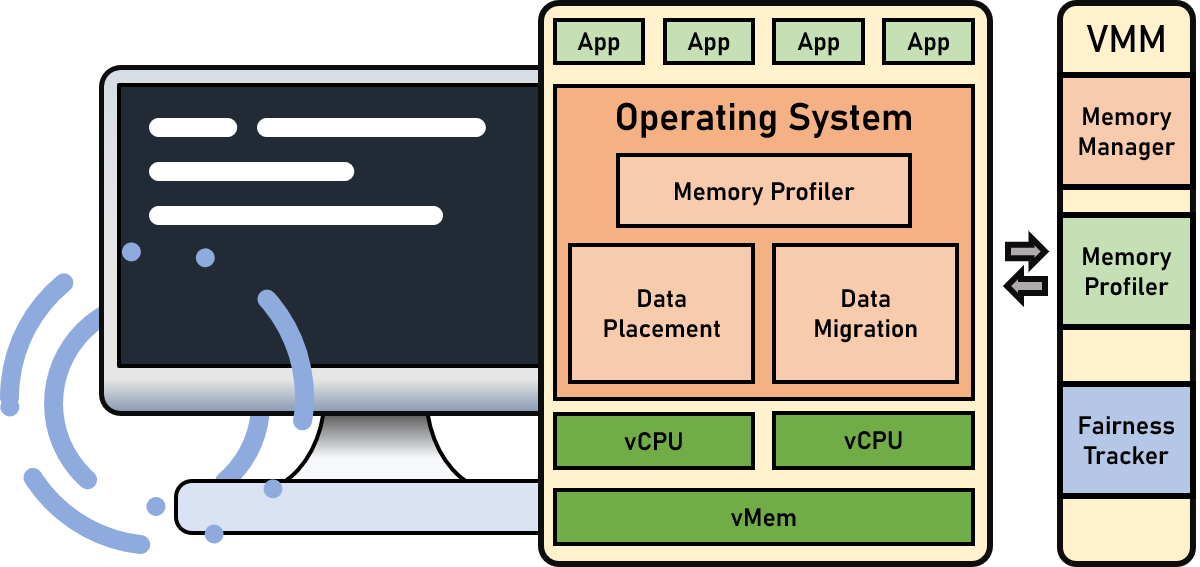
Operating Systems research explores the design and management of software that controls and coordinates hardware resources in a computing system. It focuses on optimizing core functions such as process management, memory management, file systems, and input/output control to ensure efficient and secure execution of applications.
Key areas of study include scheduling algorithms for maximizing CPU utilization, memory allocation techniques to optimize performance, and methods for managing concurrent processes.
Researchers also investigate new approaches for enhancing system security, scalability, and reliability, particularly in distributed and cloud environments. With the rise of multi-core processors and virtualization technologies, operating systems research plays a critical role in enabling efficient resource sharing and improving overall system performance.
Accelerator
Accelerator research focuses on the development and integration of specialized hardware units designed to speed up specific tasks in computing systems. Unlike general-purpose CPUs, accelerators such as GPUs (Graphics Processing Units), FPGAs (Field-Programmable Gate Arrays), TPUs (Tensor Processing Units), and custom ASICs (Application-Specific Integrated Circuits) are optimized for high-performance in tasks like machine learning, data analytics, and scientific simulations. These accelerators work alongside the CPU to offload computationally intensive tasks, significantly improving processing speed and energy efficiency.
Key research areas include designing scalable accelerator architectures, optimizing data movement between accelerators and memory, and developing software frameworks that enable seamless use of these devices in heterogeneous computing systems.
As demand for AI, deep learning, and big data grows, accelerator research becomes increasingly important in driving innovation in high-performance computing and specialized application areas.
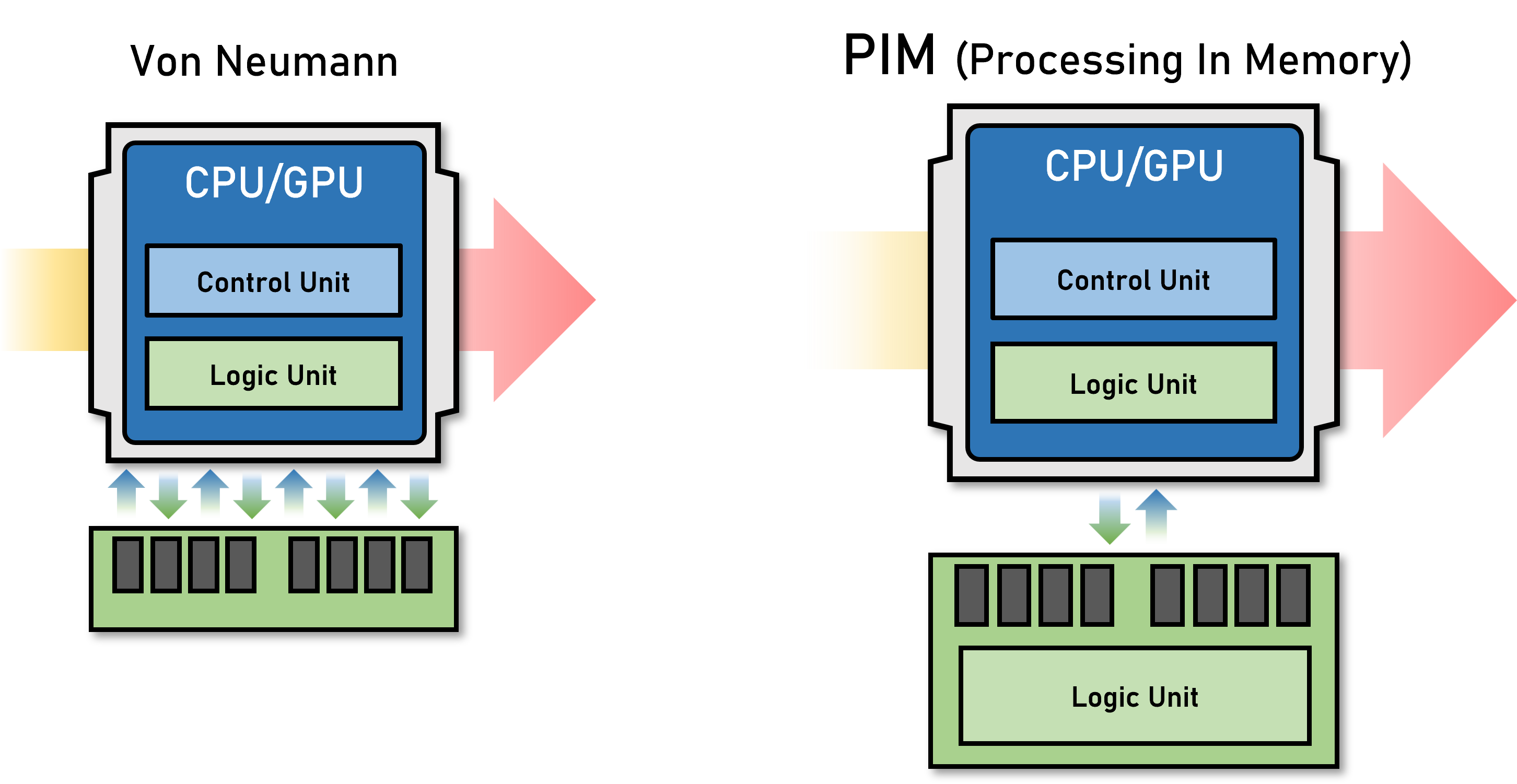
Near Data Processing / Processing in Memory
Near Data Processing (NDP) / Processing in Memory (PIM) research focuses on minimizing the data movement between memory and processors, which is a major bottleneck in modern computing systems. By bringing computation closer to the data—either within or near the memory itself—this approach reduces latency, improves energy efficiency, and boosts overall system performance.
Key areas of study include designing memory architectures that integrate processing units directly into memory (PIM) and developing algorithms that can leverage this architecture for efficient data processing. NDP and PIM are particularly useful for data-intensive applications like machine learning, big data analytics, and real-time processing, where the cost of moving data often outweighs computation.
This research is critical as it addresses the limitations of traditional von Neumann architectures, opening up new possibilities for scalable, high-performance computing systems.